
Zenseact Open Dataset
The Zenseact Open Dataset (ZOD) is a large multi-modal autonomous driving (AD) dataset, created by researchers at Zenseact. It was collected over a 2-year period in 14 different European counties, using a fleet of vehicles equipped with a full sensor suite. The dataset consists of three subsets: Frames, Sequences, and Drives, designed to encompass both data diversity and support for spatiotemporal learning, sensor fusion, localization, and mapping. Together with the data, we have developed a SDK containing tutorials, downloading functionality, and a dataset API for easy access to the data. The development kit is available on Github.
Frames consist of 100k curated camera images with two seconds of other supporting sensor data, while the 1473 Sequences and 29 Drives include the entire sensor suite for 20 seconds and a few minutes, respectively. To see examples from each of the subsets, please visit their respective pages.
Notably, ZOD is currently the only AD dataset released under the permissive CC BY-SA 4.0 license, allowing for both commercial and non-commercial use. We believe that this will help the community to advance the state-of-the-art in autonomous driving as it can enable smaller companies to use the dataset for research, benchmarking, and development. For more information about the license, see here.
News: [Jan. 27, 2025] We have added radar point cloud data to ZOD Sequences and Drives.
Annotations
Together with our dataset, we also release a comprehensive set of annotations for several different tasks. For more detailed information about the annotations, visit the Annotations page. In summary, the following annotations are provided:
- Objects: 2D and 3D bounding boxes for static and dynamic objects in the scene.
- Lane markings: Instance and semantic segmentation of lane markings and road paintings.
- Ego road: Semantic segmentation of ego-road
- Traffic signs: Classification labels with a taxonomy of 156 different traffic sign classes.
- Road condition: Classification of the road-surface condition (e.g., wet or snow).
The images below show examples of the annotations for the different tasks. Note that the images have been anonymized with Deep Neural Anonymization Technology (a.k.a Deep Fakes) to preserve the privacy of the identities in the images, including faces and license plates. For more information go to the Anonymization section.
Sensor setup
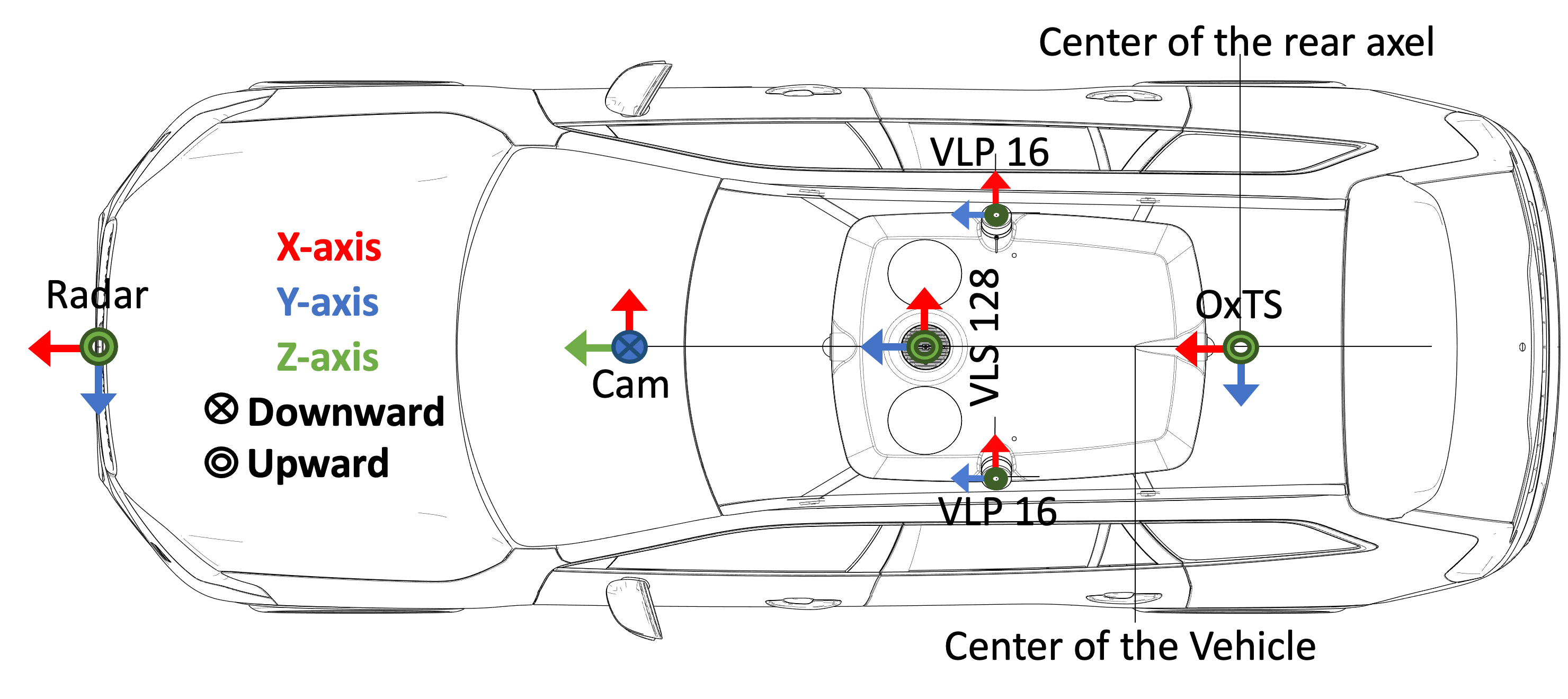 The data collection has been conducted using several vehicles with an identical sensor layout driven around Europe over two years. The cars are equipped with a high-resolution camera, 3x LiDARs, a high-precision GNSS/IMU sensor and other consumer-grade sensors. The sensor setup is outlined in the figure to the right and each sensor is described in more detail below.
The data collection has been conducted using several vehicles with an identical sensor layout driven around Europe over two years. The cars are equipped with a high-resolution camera, 3x LiDARs, a high-precision GNSS/IMU sensor and other consumer-grade sensors. The sensor setup is outlined in the figure to the right and each sensor is described in more detail below.
Camera: 1x 120° FOV 3848x2168 RGB camera.
The camera data is captured by high-resolution (8MP) wide-angle fish-eye lenses. All raw captured camera data is converted to RGB images using an internal production-level image signal processor. The RGB camera images are captured at 10.1Hz and provided as jpg files. However, if requested, we can also provide lossless png files.
LiDAR: 1x Velodyne VLS128 and 2x Velodyne VLP16.
The LiDAR point clouds are captured at ~9Hz and stored in a standard binary file format (.npy) per scan. Each file contains data from all three LiDAR sensors, represented as a 6-dimensional vector with the timestamp, 3D coordinates (x, y, and z), intensity, and diode index. The timestamp is relative to the frame timestamp in UTC, and the 3D coordinates are in meters. Intensity is a measure of the reflection magnitude ranging from 0-255, and the diode index specifies the emitter that produced the point, where [0, 128) is the VLS128, and [128, 144), [144, 160) is the left and right VLP-16, respectively. Each LiDAR point cloud contains around 254k points on average and ranges up to 245m.
Radar: Continental ARS513 B1 sample – year 2022
The radar point clouds are captured in every 60 ms and stored in a standard binary file format (.npy) for each ZOD Sequence and Drive. The data contains timestamps in UTC, radar range in meters, azimuth and elevation angles in radians, range rate in meters per second, amplitude (or SNR), validity, mode, and quality. The radar switches between three modes depending on the ego vehicle speed, and the sensor has a different maximum detection range in each mode. Mode 0 represents the radar point clouds captured when the vehicle speed is less than 60 to 65 kph with a maximum detection range of 102 meters, while modes 1 and 2 represent vehicle speeds of between 60 to 65 kph and 110 to 115 kph, and more than 110 to 115 kph, respectively, with maximum detection ranges of 178.5 and 250 meters. The azimuth angle values are between -50 and 50 degrees. The quality value also changes from 0 to 2, with 2 indicating the highest quality for the detections. The radar extrinsic calibration information (i.e., latitude, longitude, and angle) is provided in calibration files, indicating its position relative to the reference coordinate frame.
GNSS/IMU: High-precision OxTS.
The high-precision GNSS/IMU data is logged at 100Hz and stored as HDF5 files. The data has a 0.01m position accuracy, 0.03deg pitch/roll and 0.1deg heading accuracy. The data contain timestamp, latitude, longitude, altitude, heading, pitch, roll, velocities, accelerations, angular rates, and poses relative to the first pose in the file.
Vehicle data: Production-grade vehicle data
Various vehicle data are also released for Sequences and Drives. These include vehicle control signals such as steering wheel angle, acceleration/brake pedal ratios, and turn indicator status, as well as consumer-grade IMU and satellite positioning data. The vehicle control signals, IMU, and satellite positioning data are logged at 100Hz, 50Hz, and 1Hz respectively.
Anonymization
To protect the privacy of every individual in our dataset, and to comply with privacy regulations such as the European Union’s General Data Protection Regulation (GDPR), we employ third-party services (Brighter AI) to anonymize all images in our dataset. The anonymization should protect all personally identifiable information in the images, including faces and license plates.
For Frames we supply two types of anonymization, namely Deep Neural Anonymization Technology (DNAT) and blurring. We studied the effects that these two anonymization methods have on downstream computer vision tasks and found no significant difference between the two. For more details about the experiments, see our paper. After this study, we anonymized the Sequences and Drives using the blurring anonymization method only.
Two show the difference between the DNAT and blurred images, we show some examples below.
Citation
If you publish work that uses Zenseact Open Dataset, please cite our paper.
@inproceedings{alibeigi2023zenseact,
title={Zenseact Open Dataset: A large-scale and diverse multimodal dataset for autonomous driving},
author={Alibeigi, Mina and Ljungbergh, William and Tonderski, Adam and Hess, Georg and Lilja, Adam and Lindstrom, Carl and Motorniuk, Daria and Fu, Junsheng and Widahl, Jenny and Petersson, Christoffer},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},
year={2023}
}